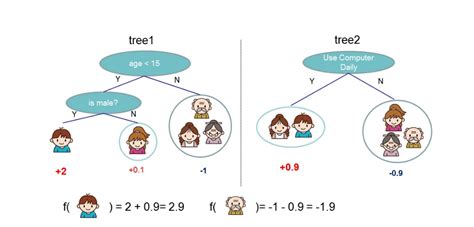
这有助于邻域保持尽可能大,以避免方差不必要地增大,而且只有在复杂结构很显然的时候才会变小 。尽管当涉及到高维问题时,树提升「打败了」维度的诅咒(curse of dimensionality),而没有依赖任何距离指标 。另外,数据点之间的相似性也可以通过邻域的自适应调整而从数据中学习到 。这能使模型免疫维度的诅咒 。
另外更深度的树也有助于获取特征的交互 。因此无需搜索合适的变换 。因此,是提升树模型(即自适应的确定邻域)的帮助下,MART 和 XGBoost 一般可以比其它方法实现更好的拟合 。它们可以执行自动特征选择并且获取高阶交互,而不会出现崩溃 。通过比较 MART 和 XGBoost,尽管 MART 确实为所有树都设置了相同数量的终端节点,但 XGBoost 设置了 Tmax 和一个正则化参数使树更深了,同时仍然让方差保持很低 。
相比于 MART 的梯度提升,XGBoost 所使用的牛顿提升很有可能能够学习到更好的结构 。XGBoost 还包含一个额外的随机化参数,即列子采样,这有助于进一步降低每个树的相关性 。本文的看法这篇论文从基础开始,后面又进行了详细的解读,可以帮助读者理解提升树方法背后的算法 。通过实证和模拟的比较,我们可以更好地理解提升树相比于其它模型的关键优势以及 XGBoost 优于一般 MART 的原因 。
因此,我们可以说 XGBoost 带来了改善提升树的新方法 。本分析师已经参与过几次 Kaggle 竞赛了,深知大家对 XGBoost 的兴趣以及对于如何调整 XGBoost 的超参数的广泛深度的讨论 。相信这篇文章能够启迪和帮助初学者以及中等水平的参赛者更好地详细理解 XGBoost 。参考文献Chen, T. and Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowl- edge Discovery and Data Mining, KDD 』16, pages 785–794, New York, NY, USA. ACM.Freund, Y. and Schapire, R. E. (1996). Experiments with a new boosting algorithm. In Saitta, L., editor, Proceedings of the Thirteenth International Conference on Machine Learning (ICML 1996), pages 148–156. Morgan Kaufmann.Friedman, J. H. (2002). Stochastic gradient boosting. Comput. Stat. Data Anal., 38(4):367–378.Hastie, T., Tibshirani, R., and Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition. Springer Series in Statistics. Springer.Kuhn, M. and Johnson, K. (2013). Applied Predictive Modeling. SpringerLink : Bu ?cher. Springer New York.Lichman, M. (2013). UCI machine learning repository.Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. The MIT Press.Strobl, C., laure Boulesteix, A., and Augustin, T. (2006). Unbiased split selection for classification trees based on the gini index. Technical report.Vapnik, V. N. (1999). An overview of statistical learning theory. Trans. Neur. Netw., 10(5):988–999.Wei-Yin Loh, Y.-S. S. (1997). Split selection methods for classification trees. Statistica Sinica, 7(4):815–840.Wikipedia::Lasso. https://en.wikipedia.org/wiki/Lasso_(statistics)Wikipedia::Tikhonov regularization. https://en.wikipedia.org/wiki/Tikhonov_regularization 。
请问现阶段的AI人工智能和大数据有多少种算法方式呢?
你好,我正好在学习研究AI人工智能,很高兴能回答你的问题 。首先,算法是无穷多的,而且每天都会有新的算法出现,不过有些算法成为了经典,也就成为我们需要学习作为基础的算法知识 。在AI人工智能领域,总体可分为传统算法和深度学习方面的算法 。传统算法都是经典算法,比如k-近邻算法,线性回归,逻辑回归,svm,主成分分析pca,决策树,随机森林,集成学习,xgboost,朴素贝叶斯算法,隐马尔可夫算法,EM算法等等 。
推荐阅读
















- 洗车行的前期投资多少,创业洗车行的逆袭之路
- 中国互联网公司排名,深圳互联网公司排名
- 雷霆之怒玉石碎片怎么刷,《雷霆之怒》玉石碎片怎么刷
- 奥拉星阿波罗众神之怒怎么打,嬴政与阿波罗平局
- 求帮忙
- 泉州房价会降价吗,泉州的房价会降价吗
- 亚运会后杭州房价上涨,2022年亚运会开完之后
- 房产限购政策之后房价还会涨吗,如果青岛的房子放开限购的话
- 文明帝国之革新怎么玩,2021年12月
- 雷霆之怒vip打宝怎么进,《雷霆之怒》刷怪荣誉任务攻略