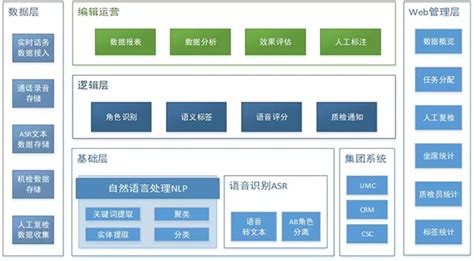
分词算法分为词典方法和统计方法,其中基于词典和人工规则的方法是按照一定的策略将待分析的词与词典中的词条进行匹配(包括正向匹配、逆向匹配和最大匹配) 。统计方法是基本字符串在语料库中出现的统计频率,典型的算法有HMM、CRF等,其中CRF相比HMM有更弱的上下文无相关性假设,理论上效果更好一些 。英文以空格为分割符,因此不需要进行分词的操作(片面看法,特殊情况仍然需要分词操作),例如一些复合词也需要识别 。
2、词性标注对于词性标注,首先需要定义词性的类别:如名词、动词、形容词、连词、副词、标点符号等等 。词性标注是语音识别、句法分析、信息抽取技术的基础技术之一,词性标注是标注问题,可以采用最大熵、HMM、CRF等具体算法进行模型的训练 。在自动问答系统中,为了提高用户问题匹配后端知识库的召回率,对一些关键词进行过滤,包括连词、副词对于全文检索系统理论上可以通过对用户输入的查询条件进行词性过滤,但由于全文检索是基于词袋的机械匹配,并采用IDF作为特征值之一,因此词性标注的效果不大 。
3、句法分析句法分析的目的是确定句子的句法结构,主谓宾、动宾、定中、动补等 。在问答系统和信息检索领域有重要作用 。4、命名实体识别命名实体识别是定位句子中出现的人名、地名、机构名、专有名词等 。命名实体属于标注问题,因此可以采用HMM、CRF等进行模型的训练 。基于统计的命名实体需要基于分词、词性标注等技术 。
实体命名定义了五大类型:设施(FAC)、地理政治实体(GPE)、位值(LOC)、人物(PER) 。在实际应用中,可以根据自己的业务需求,定义实体类别,并进行模型训练 。5、实体关系抽取实体关系抽取是自动识别非结构化文档中两个实体之间的关联关系,属于信息抽取领域的基础知识之一 。近年来,搜索领域流行的知识图谱技术是构建实体关系 。
人工智能自然语言处理就业形势与行业发展前景如何?
自然语言处理与计算机视觉、私人虚拟助理、智能机器人和语音识别一起并成为未来国内人工智能行业发展的五大趋势 。从投资来看,自然语言处理也是获得投资最多的领域之一 。人工智能不断发展,对金融行业分析也能起到至关重要的作用,比如关注市场变动线索、预测价格趋势、评估市场风险等,但要、人工智能在金融行业真正实现全场景落地,首先要搞定的就是自然语言处理技术 。
这一技术是关键,也是难点 。自然语言处理能实现计算机与人之间的自然语言交流,是一门融语言学、计算机科学、数学于一体的科学,是计算机科学、人工智能、语言学关注计算机和人类语言之间相互所用的领域 。说白了就是让人工智能可以听懂人话 。随着智能领域的产业分工日渐明确,各大企业已经从最开始的竞争模式转为了合作模式,实现双赢,自然语言处理技术这一块也越来越被大家所看好 。
可预见的是,未来二十年内,自然语言处理将会成为人工智能应用最大的突破口之一,最近知识图谱在搜索领域已经有一席之地,并在火速推广中,一种是要关联很多领域,一种是进行知识整合,这样看来未来很有可能将自然语言处理与知识图谱相结合的趋势 。上面也说了人工智能自然语言处理所涉猎到的技能和技术领域非常广泛,毫不夸张地说,一名自然语言处理工程师一定是个全能型人才,要掌握大部分的人工智能领域技术,所以真正从事这方面的人才也非常少,现在社会上从市自然语言处理的人大部分都是非科班出身,不是工作中自学的就是跟着项目一起摸爬滚打出来的,所以从事自然语言处理的专业人士,行业发展是非常客观的 。
推荐阅读














- Pro功能大盘点,三星c9pro处理器
- 苹果6 12,iphone12处理器是多少
- 奔腾双核的处理器 t420i,Thinkpad的T420i的电脑性能等怎么样? 后面带i...
- 万和热水器e4故障处理
- 性能最好的手机,截止2021年最好的几个手机处理器?
- 990与985处理器区别
- 泰迪小狗爪子怎么剪,主人知道怎么处理
- 挂式空调室内机漏水怎么处理,空调滴水是什么原因 挂机室内漏水怎么办
- intel酷睿八代处理器怎么样,Intel第八代酷睿i5
- 英特尔i77700hq怎么样,7700HQ的处理器怎么样