因此人体骨骼关键点检测是诸多计算机视觉任务的基础,例如动作分类,异常行为检测,以及自动驾驶等等 。近年来,随着深度学习技术的发展,人体骨骼关键点检测效果不断提升,已经开始广泛应用于计算机视觉的相关领域 。本文主要介绍2D人体骨骼关键点的基本概念和相关算法,其中算法部分着重介绍基于深度学习的人体骨骼关键点检测算法的两个方向,即自上而下(Top-Down)的检测方法和自下而上(Bottom-Up)的检测方法 。
相应算法的详细介绍大家可以关注我头条号之前发布的文章.文字识别OCROCR(Optical Character Recognition, 光学字符识别)传统上指对输入扫描文档图像进行分析处理,识别出图像中文字信息 。场景文字识别(Scene Text Recognition,STR) 指识别自然场景图片中的文字信息 。
我这里主要介绍难度更大的场景文字识别的发展.自然场景图像中的文字识别,其难度远大于扫描文档图像中的文字识别,因为它的文字展现形式极其丰富:·允许多种语言文本混合,字符可以有不同的大小、字体、颜色、亮度、对比度等 。·文本行可能有横向、竖向、弯曲、旋转、扭曲等式样 。·图像中的文字区域还可能会产生变形(透视、仿射变换)、残缺、模糊等现象 。
·自然场景图像的背景极其多样 。如文字可以出现在平面、曲面或折皱面上;文字区域附近有复杂的干扰纹理、或者非文字区域有近似文字的纹理,比如沙地、草丛、栅栏、砖墙等 。文字识别其实主要包含两个步骤, 文字检测与文字识别, 但是近年来也有出现了以CRNN(具体可以关注华中科大白翔老师的研究)为代表的一步到位的端到端的识别模型,效果也还不错.文本检测工作目前可以大致分为三类:一是基于分割的思想,通过分割网络提取文本区域,然后采取一些后处理方法获取边界框 。
代表性的工作是发表在CVPR2016的“Multi-oriented text detection with fully convolutional networks”;二是基于候选框的思想,直接用一个神经网络来检测文本边界框 。代表性的工作是发表在CVPR2016的“Synthetic data for text localization in natural images”;三是混合思想,它采用多任务学习的框架,结合了分割和边界框检测的方法 。
代表性的工作是发表在ICCV2017的“Deep Direct Regression for Multi-Oriented Scene Text Detection” 。而文字识别大致分为两类思路:其一是从单词或字符层面入手,设计单词分类器或字符分类器,将每一个单词或字符作为一类目标,进行多类别分类任务 。
而近来循环神经网络大放异彩,它可以将文本识别看作一个序列标签问题,并能够直接输出标签序列 。因此,第二种思路从序列层面入手,将文本看作一个字符序列,通过设计序列特征提取器,结合循环神经网络(RNN)和CTC模型,将文本序列作为一个整体进行识别 。目前OCR方面比较经典的算法有CTPN,RRPN,DMPNet,SegLink,TextBoxes,FTSN,WordSup等, 具体可以关注我头条号,我后面会推出详细介绍.总结以上内容总结了目前计算机视觉方向比较流行的方向,以及一些经典的算法.能力有限,难免有总结的不到位地方,欢迎指正.最后,欢迎大家关注我的头条号,会有大量深度学习相关资源不间断放送. 。
传统的CNN为什么深度越深的时候效果不好,残差网络却可以克服这问题?
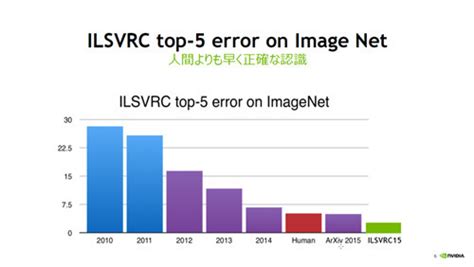
至少针对图像规模而言,首先一个共鸣就是:搜集越深了局越好,比方本年ILSVRC2015的MSRA秒天秒地的成效可见一斑 。而传统的深层神经搜集是做不到这么深的,一个首要缘故原由就是剃度会弥散可能爆炸 。怎么休止传统深层神经搜集中呈现的剃度弥散可能爆炸能够参照batch normalization等要领 。今朝常用的深层神经搜集之以是比之前的好,如CNN,大年夜略说来就是:(1)权值共享使得模型越发大年夜略,泛化伎俩更强;(2)局部毗邻使得对feature的抽象历程大年夜大年夜裁减了对空间干系性对依靠,使得模型对样本的畸变不敏感(如改变、扭曲等) 。
推荐阅读













- 三国杀孙策怎么对付,孙策惨遭史诗级削弱
- 贪玩蓝月页游怎么破解vip,《贪玩蓝月》秘密套路遭破解
- 什么电子狗最好,电子狗惨遭丢弃
- 何享健,MBA智库百科
- 王璐瑶发微博遭网暴,王帆微博
- 名创优品遭遇了什么,上海名创优品电话是多少钱一个
- 消费者网购信息遭泄露,如何进行消费者个人分析
- 合肥限购下房价遭夭折,合肥放开房子限购了吗
- 遭狗儿咬了怎么办,狗儿被咬怎么办
- 导游贞,苏菲亚的遭遇