分完以后怎么样,老师也很有好奇心,让他们继续分下去,想看看最后会怎么样 。这样分了n轮后,假设小红小绿小蓝的糖果数分别是Xn、Yn、Zn,因为分法是不变的(也就是分的概率不变),所以每次的结果只和上一次有关 。这是什么,这就是线性变换(比如主成分分析和非负矩阵分解都是一种线性变换),将一个向量变成另一个向量,矩阵就是线性变换矩阵,下面就是矩阵形式 。
将未知向量记为Pn,系数矩阵记为A,则有下面更简单的形式Pn 1=APn使用递推公式可得Pn=A的n次方乘以P0,可以看出,这和矩阵A有关,或者说和A的n次方有关 。在马尔科夫链里,这个矩阵叫转移矩阵,具体到分糖果发现从60次开始往后小红小绿小蓝的糖果数趋于稳定,三个人是5、8、5 。而且,最后的这个稳定状态和刚开始你有多少糖果无关,只和转移矩阵有关 。
那么,这个和搜索有什么关系,搜索时如何把用户想要的网页呈现给用户?如何衡量网页的重要性呢?在悟空问答里可以用点赞数评论量来衡量,问题是用户看网页时一般没有点赞和评论,那怎么办?用链接到这个网页的网页数来衡量这个网页的重要性,就跟一篇文章引用次数越高质量越好一样 。现在假设包含同一关键词的网页总共有N个,每个网页都链接到某些网页,这样就得到了转移矩阵,由稳定性可知,经过若干次转移后趋于稳定,这样就得到了所有网页权重的一个稳定状态,此时进行排名即可,是不是很神奇?这就是谷歌搜索的Pagerank算法,由谷歌创始人之一拉里佩奇提出 。
文本挖掘的方法主要有哪些?
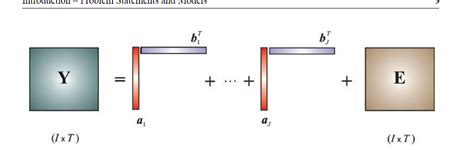
文本挖掘一直是十分重要的信息处理领域,因为不论是推荐系统、搜索系统还是其它广泛性应用,我们都需要借助文本挖掘的力量 。每天所产生的信息量正在迅猛增加,而这些信息基本都是非结构化的海量文本,它们无法轻易由计算机处理与感知 。因此,我们需要一些高效的技术和算法来发现有用的模式 。文本挖掘近年来颇受大众关注,是一项从文本文件中提取有效信息的任务 。
由于以各种形式(如社交网络、病历、医疗保障数据、新闻出版等)出现的文本数据数量惊人,文本挖掘(TM)近年来颇受关注 。IDC在一份报告中预测道:截至到2020年,数据量将会增长至400亿TB(4*(10^22) 字节),即从2010年初开始增长了50倍[50] 。文本数据是典型的非结构化信息,它是在大多数情况下可产生的最简单的数据形式之一 。
人类可以轻松处理与感知非结构化文本,但机器显然很难理解 。不用说,这些文本定然是信息和知识的一个宝贵来源 。因此,设计出能有效处理各类应用中非结构化文本的方法就显得便迫在眉睫 。目前现在的文本挖掘方法主要有:1. 信息检索(Information Retrieval,IR):信息检索是从满足信息需求的非结构化数据集合中查找信息资源(通常指文档)的行为 。
2. 自然语言处理(Natural Language Processing ,NLP):自然语言处理是计算机科学、人工智能和语言学的子领域,旨在通过运用计算机理解自然语言 。3. 文本信息提取(Information Extraction from text ,IE):信息提取是从非结构化或半结构化文档中自动提取信息或事实的任务 。
4. 文本摘要:许多文本挖掘应用程序需要总结文本文档,以便对大型文档或某一主题的文档集合做出简要概述 。5. 无监督学习方法(文本):无监督学习方法是尝试从未标注文本中获取隐藏数据结构的技术,例如使用聚类方法将相似文本分为同一类 。6. 监督学习方法(文本):监督学习方法从标注训练数据中学习分类器或推断功能,以对未知数据执行预测的机器学习技术 。
推荐阅读














- 海尔卡萨帝热水器,海尔刚出来的卡萨帝热水器质量怎么样求维修过此种热水器人分解
- AV矩阵切换器,av矩阵切换器
- 灭神怎么分解守护,《灭神》今日激燃公测
- 求根公式的分解方法和特点有哪些?你完全掌握了吗?
- 战神三十六计怎么分解马超,均用了三十六计中哪一计
- 对称矩阵的值怎么求,矩阵的值怎么求
- 什么能分解蛋白质污渍
- 为什么洗洁精能分解食用油
- 什么是媒体矩阵,矩阵是什么
- 分解质因数的方法求最小公倍数,分解质因数的方法