爬虫工程师薪资怎么样?
作为一位老爬虫工程师 , 也面过不少应聘者 , 了解基本的行业行情 。先做总结:爬虫相对来说是一个比较有前景的工作 , 但是不推荐普通人来做 , 相对于前后端等业务 , 爬虫的后续发展(对抗能力)是很急缺的 , 然而这种能力是需要天分和大量的汗水的 , 随着人工智能和5G的到来 , 大厂的反爬策略会越来越多样化 , 那时候普通业务的爬虫将会面临爬不到数据的尴尬 , 而那些具有对抗能力的逆向工程师将会有更高的待遇 。
首先:爬虫工程师的工资和前后端的薪资标准是差不多的 , 10—15K(广州)是一个基本区间 , 这部分区间的能力基本要求较低 , 属于业务类型的工作 , 技术栈:抓包工具 , scrapy等爬虫框架 , selenium或者pyppeteer等浏览器渲染的工具 , 要求高点的需要前端比较熟 , 逆向前端的加密接口 。这部分其实还是属于一个普通开发者阶段 , 并不涉及多高明的技术内容 , 很多大数据开发或者算法岗都说自己会爬虫 , 也基本属于这个阶段 。
即应付普通业务 。第二个阶段:对抗阶段(逆向工程)是爬虫的后续发展 , 其实大部分人走不到这里 , 原因很简单 , 逆向是个很复杂而且很无聊的工作 , 不管是JS逆向还是安卓逆向最基本的操作都是混淆 , 很多人面对a,b,c,d等各种函数名就觉得头疼 , 没有耐心根本不可能找到加密规则 。大部分在这个阶段都可能会选择做全栈 , 后端 , 前端等业务方向 , 毕竟业务其实是最简单的 。
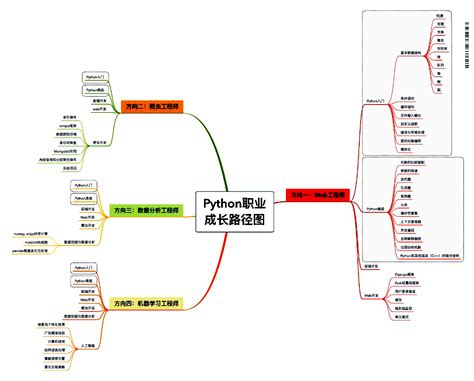
爬虫工程师要学什么技术?

爬虫工程师的起点是数据获取 , 提升是数据分析 。1、数据获取显然这个也是爬虫工程师叫法的来源 。现在最流行的爬取语言都是Python 。所以首先要学习 Python 的基础语法 , 然后掌握 request、xpath、bs4 等常用的爬虫库 。掌握了这些技术就可以进行简单的网站爬取了 。大致的爬虫流程分为:分析网站请求、发生请求、解析数据、存储数据 。
这些根据实际业务需要进行就可以 。一般情况下网站是不希望我们随便爬取的 。我们不可能像谷歌 , 百度那样 , 严格的执行robot协议 。相反 , 爬虫工程师的核心价值就体现在对反爬措施的攻克 。各种伪装 , 包括:网络数据包伪装 , 验证码破解等等 。总之就一句话 , 伪装成个人 , 不能让网站发现我们是机器 。这里面涉及人工智能 , 图像学 , 网络通信等等技术 。
如何才能成为一名爬虫工程师?
一、爬虫工程师是干嘛的?1.主要工作内容?互联网是由一个一个的超链接组成的 , 从一个网页的链接可以跳到另一个网页 , 在新的网页里 , 又有很多链接 。理论上讲 , 从任何一个网页开始 , 不断点开链接、链接的网页的链接 , 就可以走遍整个互联网!这个过程是不是像蜘蛛沿着网一样爬?这也是“爬虫”名字的由来 。作为爬虫工程师 , 就是要写出一些能够沿着网爬的”蜘蛛“程序 , 保存下来获得的信息 。
推荐阅读











- 手机像素,2500~2999
- 【今日话题】你们的旧手机怎么处理了?
- 选一个你称心如意的浏览器
- T3?
- 滕州今日房价走势,滕州明年房价走势
- 盒子桌面软件哪个好,电视盒子和第三方软件哪个好
- 大搜车怎么样,大搜车怎么样谁知道
- 干洗店加盟装修,ucc怎么加盟
- 对组织部的认识怎么写,组织部介绍怎么写
- 手机在哪,轻松帮你找到手机