【和批梯度下降算法,随机梯度下降】随机梯度下降算法是什么?
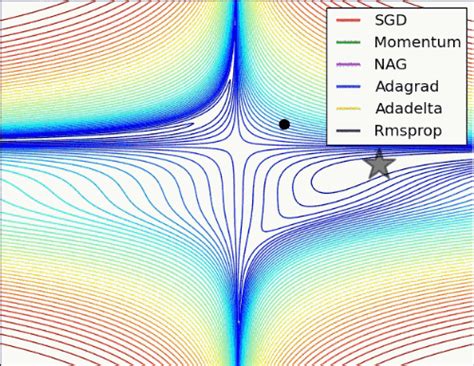
随机梯度下降算法是基于梯度下降法中最原始的方法——批量梯度下降法(BGD)的缺点而演变出的改良 。在训练过程中常见的损失函数为:批量梯度下降法(Batch Gradient Descent,简称BGD)的方法是先求偏导,再用每个θ各自的梯度负方向依次更新每个θ:它的效果如图:可以看出是一种思路简单、易于实现的算法,并且在较少迭代次数的情况下就可以得到全局最优解,但是每次迭代都要调用全部数据,如果样本数量(上面式子中的m)较大,将会导致计算极其慢 。
基于这一缺点,随机梯度下降法(Stochastic Gradient Descent,简称SGD)被提出 。它不再每次迭代都用上所有样本,而是每次迭代仅仅对一个样本进行更新,从而达到对于数量庞大的样本只需使用其中的相对少量就把θ最优化的目的 。它的方法是在改写损失函数之后,θ的更新是基于每个样本对theta求偏导后所得梯度:相比BGD算法SGD算法速度大幅提升,几十万条样本基本只需要用上万或者只要上千条样本就饿可以得到结果 。
但是SGD伴随更多噪音、最优化方向准确度下降的问题 。效果如下图,可以看出相比于BGD,SGD迭代次数显著增加,并且并不是每一次迭代都是向着最优化方向 。同时,SGD算法在实现难度上不如BGD算法简单 。虽然理论上BGD比SGD得到全局最优,但是在生产场景中,并不是每一个最优化问题中的目标函数都是单峰的,反而是sgd更容易跳出局部最优 。
机器学习中的batch_size越大越好吗?
从实际中来看,这个问题并没有统一的正确答案,需要具体问题具体分析 。但是这里可以分享一些实际训练训练中的经验 。Batch size,批大小也就是模型在每次训练时,喂给他多少的数据量 。通常我们优化模型所使用的损失函数公式如下,优化的目标往往是非凸函数,因此存在诸多的局部最优点 。其中M就是全部的训练数据大小,f(x)是单个数据的损失函数 。
而在我们每次更新模型参数时,所用的计算公式如下:这里的Bk就是批大小,Bk是小于等于M的 。而按照选取的Bk大小,我们可以将其分成三类:1. Bk=1,即随机梯度下降,即每次针对单个数据进行参数更新 。这种方法的优势在于占用的内存很小,能够实现在线学习 。弊端也很明显,就是很容易由于梯度方向的随机而导致模型无法收敛,而且无法充分并行计算,训练时间过长 。
2. Bk=M,即每次都使用全部数据来进行模型参数的更新,这种方式在每次更新时,得到的更新梯度方向更加准确,使得模型收敛的更加稳定 。但是缺点在于,当数据量非常大的时候,由于内存的限制,往往无法实现,同时所需要训练的epoch数也会大大增加;3. 1
推荐阅读















- MBA智库百科,运营商
- 苹果平板6代参数,ipad五代和六代的基本参数是一样吗
- vivos12配置参数,请问步步高vivoS12的数据线和哪种手机的一样通用我想买数据线但
- paperfree官网入口,paperfree和大雅哪个论文检测系统好用一些
- iphonese什么处理器,iPhoneSE能不能撑到和6s同一个时期淘汰
- 佳能70d配1740镜头怎么样,佳能70d拍人像和风景
- 地球和月球 哪个大,地球大还是月球大
- 近义词和反义词有哪些,偏颇
- 专门看手机的app,请问有什么软件可以知道别人的手机的来电和信息注他手机来
- 苹果11和12绿色对比,妈妈买回来30个苹果第一天吃了8个这些苹果比原