
文章图片

文章图片

文章图片
文章图片

文章图片
文章图片
文章图片

文章图片
文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

01 为什么要做业务观测
先简单介绍下内容创作业务概要 。
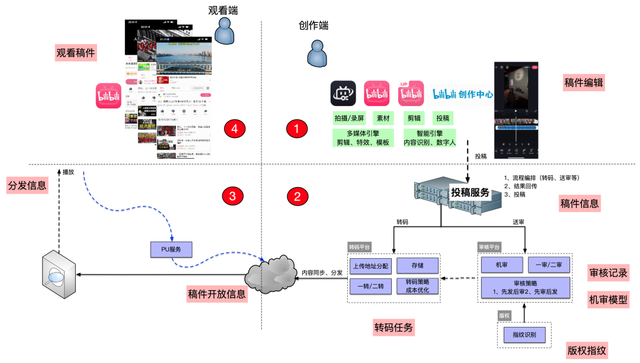
UP主创作的视频内容最终会以\"稿件\"为载体进行打包投稿 。
一个稿件从创作到最终用户能观看到 , 需要经过非常多的环节 。
从UP主的创作灵感构思 , 到视频剪辑 , 到创作完成之后进行投稿 , 投稿之后再经过一系列内部的加工 , 最终C端用户能浏览观看 。
这些创作工作 , 都可以通过B站的集成创作工具来闭环完成 。
这些流程专业的细化下来 , 主要包括 。
创作(bilibili粉版、B剪等) → 视频上传(原片上传) → 投稿(封面+标题+简介等) → 转码(分辨率等) → 内容安全审核(黄暴恐+版权等) → 稿件开放(完成生产)→ 稿件分发(CDN分发)
在整个流程中 , UP主一旦投稿 , 后续所有流程的输入输出都是围绕【稿件(archive)】业务实体(bussiness entity)展开 。
将这样的内容创作的平台能力 , 类比到制造业的生产过程 , 非常类似制造业的MES系统(Manufacturing Execution System) 。
- 制造执行系统 (MES) 是一种基于软件的解决方案 , 用于在制造过程中监控和控制车间的生产流程 。
- MES 系统的主要目的是实时跟踪和记录原材料到成品的转变 。 它从各种来源(包括机器、传感器和操作人员)捕获数据 , 以提供有关生产活动状态的准确和最新信息 。
为什么要类比MES系统 , 很重要的一点就是生产过程的【实时跟踪-调度】是一个非常科学的生产决策单元 , 可以复用到任何形式的生产系统中 。
在目前这个降本增效大环境下 , 提高生产效率显得非常重要 。 要想达到这个目标 , 平台一定需要有很强且经济的资源观测和调度能力(类似制造业的MES) 。
在一些特殊的时期或者时间段 , 会有非常多的黑灰产用户、稿件在消耗平台有限资源 。
这些黑灰产用户的稿件量也是非常大 , 如果我们没有相应的手段干预 , 会严重挤兑正常用户的稿件生产 。
对于这类有问题的用户或稿件 , 平台安全体系是有办法识别出来的 , 但是识别出来之后 , 作为内容生产平台需要有对应的功能机制可以做对接 , 来联动资源干预 。 (降权、控制速率等)
目前平台内部各个流程分工其实已经很精细化了 。
因为分工很精细化 , 一个稿件的生产加工需要经过非常多的子系统子模块 , 也让这个过程变得很黑盒 。
完整的流程要比这个复杂的多得多 。 一个稿件从无到有 , 需要经历大概几十个子流程 , 跨越多个业务领域 , 多个子系统 。
我们经常被一些问题困扰:
1.平台每天生产的稿件中 , 优质、大V、党央媒、商单稿件的生产效率如何?有没有被block?
2.下游转码、审核、开放等抖动 , 对大盘影响多少?绝对值多少?又有多少重点稿件受到影响?
3.某个大V的稿件迟迟没开放 , 知道卡在哪个环节了吗?如何主动发现?
4.所有开放的稿件 , 是否全部进行过安全审核?有没有漏审?
5....
上述这些问题正是缺乏有效的业务观测能力导致 , 我们需要实现一种可以zoom-out+zoom-in的业务观测能力 。
zoom-out 可以看到生产效率的分位统计 , 各种原因被block的稿件 , 耗时大于xxx的稿件或流程 。
zoom-in 可以快速拉取某一个稿件的全部生产事件 , 并且能看到每一个事件的当时相关信息 。 (全链路event sourcing审计能力)
如果我们能够观测到问题 , 对于优化和快速恢复 , 现有的能力和工具箱已经完全具备了 。
02 顶层设计
【何为业务观测】
我们的重点是“业务“观测 , 但是对于业务观测业内并没有一个统一的定义 , 每个人对业务观测的认知也不同 。
往往一提到观测 , 大家很惯性的会通过各种技术指标(qps、rt等)来衡量业务系统的健康状况 。
通过简单的企业分层架构来展开系统调用 , 基本上就这几个环节 。
公司的基础设施(caster平台、cloud平台、go-common框架、Bxx脚手架等)已经覆盖了【1】、【2】、【4】环节 。
这些观测的目标都是基于【服务质量】技术属性来设计的 , 【请求成功率】、【请求响应时间】、【请求的吞吐量】等 。
那么【1】、【2】、【4】都符合预期时 , 【3】是否符合预期?答案是不一定(逻辑bug、配置错误、外部因素等) 。
如果把我们的系统比喻成制造业的【生产传送带】 , 【1】、【2】、【4】是传送带本身 , 【3】是传送带上的货物 。
通过对【1】、【2】、【4】观测是无法判断【货物运送是否成功】、【运送效率】等生产情况 。 (可能有些货物一直没领取 , 也或者传送带上没有货物 , 一直在空转)
业务观测的重点是观测【3】的链路 , 专业讲就是聚焦企业经营层面 , 观测的主体是“业务实体”、“业务事件” 。
【找到观测对象】
内容生产的核心业务实体是“稿件(Archve)” , 业务观测的目的就是跟踪稿件实体生命周期 。
这是一个精简后的稿件对象结构 。 稿件基本信息加上一组视频组成稿件核心聚合 。 (真实的业务要复杂的多 , 但是不影响我们理解业务观测) 。
从业务建模角度讲 , 通常需要有四部分元素构成一个基本【聚合对象】 。
人-事-物(Party\\Place\\Thing)、角色(Role)、描述(Description)、时刻时段(MomentInterval) 。
建模大师 Peter Coad 的《Java Modeling In Color With UML》 书中 , 介绍的“四色建模”法 , 通过四种颜色代表这四种原形(archetype)对象
【人-事-物(PartyPlace or Thing)】
表示的是一种客观存在的事物 , 一般也是重要的实体Entity 。 (人、产品、物体等 , 不仅包含名词 , 还有动词都是可以作为实体建模)
【角色(Role)】
用来赋予实体Entity的角色 。 不同的角色具备不同的能力和行为 。 (只有角色赋予对象行为能力)
【描述(Description)】
用来描述Entity的分类、属性等 。 一般都是这类Entity共有的属性信息(类型、颜色等) 。
【时刻时段or关键时刻(Moment-Interval)】
以上三种原形都是静态的 , 将这些原形联动起来就是时刻时段 。 (某个人-uid , 用什么身份-up主 , 在xxx某个时刻 , 创作了一个稿件)
在业务建模时 , 构成实体的静态对象一般比较容易捕捉 , 而发生时的【时刻时段】很容易忽视 , 恰恰它才是系统的灵魂 。 (下图粉色部分)
时刻时段模型 , 在业务场景不复杂的情况下 , 一般会通过简单的log方式来处理 。 (从业务建模角度讲 , 它是客观存在的 , 落地时可以选择提炼强度)
我们将整个稿件的生命周期展开 , 这些领域都有自己核心的聚合Entity , 这些领域特定的核心Entity与稿件Entity发生联系 , 产生不同视角下的【时刻时段】 。
在转码侧 , 会有转码相关【时刻时段】 。 在审核侧 , 会有审核相关【时刻时段】 。 在开放侧 , 会有开放相关【时刻时段】 。
将这些不同领域中的核心Entity的时刻时段 , 整体关联起来就是一个稿件Entity的完整的生命周期 。 (也就是稿件的完整时刻时段)
一个稿件的生命周期 , 会经过很多系统 。 无数个与之关联的Entity(逻辑上) , 每个Entity又有N多个处理事件 , 每个事件产生对应的【时刻时段】 。
所以 , 将这些全局分散的【稿件-时刻时段】收集起来 , 就可以还原稿件的生命周期 。
【如何端到端】
我们要做的是全链路业务观测 , 要想将全局收集的所有事件串联起来 , 就需要某种trace机制 。
“业务trace” , 无法直接复用某个trace技术框架(如opentrace)来完成 。
因为业务流程都是异步长事务的 , 没有办法直接关联一次系统调用 。 一定是需要某种全局业务ID才行(如 , 订单OrderID) 。 在我们场景中 , 稿件AID就是这种全局ID 。
在整个链路中 , 投稿前用户基本都是在端上进行创作 。 获取素材 , 编辑剪辑等 , 然后导出视频原件并且上传 。
创作过程并没有稿件 , 稿件是创作完成之后才有 。 那么创作过程的事件信息就需要一种载体进行收集 , 最后才能与稿件载体的事件信息关联上 , 这个可以通过抽象某种trace实体来完成 。
如何将客户端的事件和服务端时间关联起来 。
用户在端上的所有事件通过某个TraceID单独上报 , 最后提交稿件时将这个端上的TraceID透传给服务端与之关联 。
要想端到端完整还原一个trace , 需要将提交稿件时的那一刻的服务端traceid和客户端traceid做mapping , 因为这一刻稿件实体并没有创建出来 , 客户端的所有事件信息在客户端的traceid下上报的 。
串联整个trace过程需要分为两步 , clientTraceID → serverTraceID , serverTraceID → AID 。 一旦有了AID之后 , 而AID就是一个天然的TraceID 。
03 架构设计
【收集事件流】
全局上所有的事件在不同的领域里发生着 , 不断的产生事件流(event-streaming) , 虽然逻辑上是分不同的流程 , 但是物理上是并行离散的 。
要想还原整个稿件的事件trace , 需要收集和沉淀这些事件流 , 最终形成基于事件流的底座平台 。 (理论上 , 通过对所有事件回溯【event-sourcing】可以看到稿件不同阶段的【snapshot】)
有了这套松散的 , detail级别的事件流数据 , 可以基于这套事件流观测到step1 → step2 → step3...的处理过程 。
所有创作单元分别独立上报产生的event-streaming , 后端就可以通过AID进行全局关联 。
客户端在投稿前(还未产生AID)会调用很多后端接口 , 这些接口中会统一安装【traceid绑定的midware】(自动将client_trace_id和server_trace_id做映射) 。
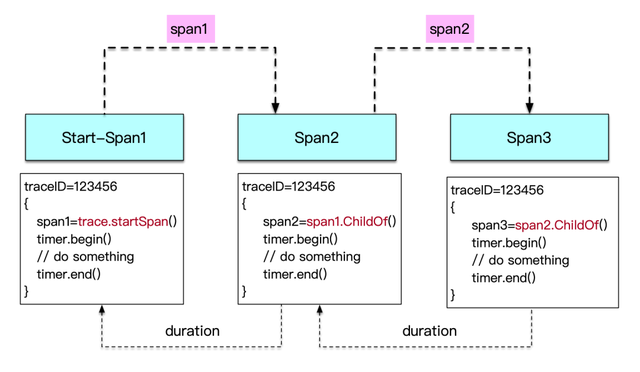
在客户端视角看来 , 这个过程非常类似OpenTrace协议中的 tracer.StartSpan(\"sub_method_1\" opentracing.ChildOf(parentSpan.Context())) 调用 。
parentSpan:=tracer.StartSpan(\"稿件创作\")//step1
parentSpan=tracer.StartSpan(\"获取素材\" opentracing.ChildOf(parentSpan.Context()))//step2
parentSpan=tracer.StartSpan(\"上传视频\" opentracing.ChildOf(parentSpan.Context()))//step3
parentSpan=tracer.StartSpan(\"稿件预检\" opentracing.ChildOf(parentSpan.Context()))//step4
parentSpan=tracer.StartSpan(\"提交稿件\" opentracing.ChildOf(parentSpan.Context()))//step5
服务端的调用入口处需要将后端的opentraceID与客户端带过来的traceID做好mapping , 并且完成上报 。
沉淀到【内容生产实时事件流平台】的事件具备全局关联性 , 而不是互相独立的孤立数据point 。
有了可以链接起来的事件 , 就可以很容易的推断出每一个step的耗时和缺失 。
可以还原某一个稿件的所有event-trace , 并且可以通过在event-trace time-line 上行走观察不同生命周期下的稿件实体的snapshot 。
整个事件序列是可以逐步细化和增加的 , 但是每一个事件最好是关键状态变更事件 。
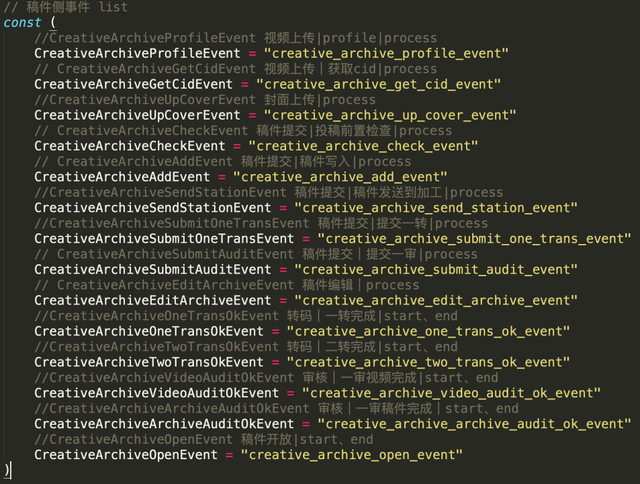
这是投稿领域的事件list , 通过这些事件流的收集 , 就可以还原投稿在投稿上的event-trace(事件中可以携带当前上下文) 。
【客户端时间问题】
后端的事件流上报时间是机器时间 , 由于服务端全局时间是NTP(Network Time Protocol)来同步保证的 。 虽然有概率延迟 , 但是绝大部分能满足我们的需求 。
客户端的绝对时间不准确 , 可能由于各种原因导致 。 采用最原始的每个方法独立上报 , 事件顺序将会发生错误 , 事件之间的duration也不准确 。
解决这个问题 , 需要通过相对顺序来设计客户端span(和Opentrace协议很类似) 。 在事件序列排序时 , 客户端部份通过相对顺序排序 , 服务端通过绝对时间排序 。
这种实现方式对上报时机有了一定要求 , 对存量代码会有一定的侵入性 , 需要部份代码重构和模块化 。
【实时数据收集与存储】
事件流上报之后 , 需要实时性的聚合存储 , 目前每天产生大概几个亿的事件流 , 平均QPS达到几k , 峰值已经上万 。
事件流的核心价值就是近实时性 , 我们使用Kafka+Flink+CK方案 。
整个事件上报走的是公司基础平台 , 链路比较长且复杂 。 平台能力作为PAAS开放 , 所以还是需要有非常多的对接和开发工作(比如 , Flink-SQL数据格式转换、Hive存储、Kafka-proxy丢失率、任务SLA提升等) 。
但是对于应用层来说 , 通过统一的设计 , 屏蔽底层实现 , 对外提供一个简单标准的sdk和上报数据协议 。
整个接入前端会通过专门的sdk来完成收集 , 相关业务方可以自由的上报自己希望全局trace起来的事件 。
extendsInfo := ts.EventExtendsInfo(te.Method \"AegisArchiveAuditing\" \"archiveState_old\" oldState \"archiveState_new\" newState \"force\" force
\"title\" title \"cover\" cover \"desc\" desc)
ts.Trace(c ts.EventTraceName(\"审核通过\") ts.EventKey(te.CreativeArchiveAuditEditEvent) ts.EventNodeType(ts.Start) ts.EventLevel(ts.Info) ts.AID(aid))
对于接入用户方来说 , 一两行代码就可以完成上报 , 至于背后的数据怎么传输和存储无需太多关注 。
接入到实时事件流平台之后 , 会自动享受到很多好处 。 事件之间的间隔计算 , 自动巡检出事件丢失 , 自动事件trace编排等能力 , 这些都不用去重复实现 。
除了事件本身的各种应用之外 , 还会享受到基于事件流平台的配套服务(排障问诊台和异动感知) 。
【异动感知与快速问诊】
观测跟踪的主体都是稿件 , 不同的事件集合都属于某个领域 , 某个领域属于某个业务部门和组织 。 不同的事件段由不同的部门来保障 。
有了这一套实时的全链路观测能力之后 , 可以针对不同的业务方向开发很多通用能力(【关键事件丢失】、【安全对账】等) 。
会发现很多比较隐蔽的问题 , 特别是全局一致性问题 。 (如 , 投稿完成发现视频没传上来等)
这些问题需要有一种机制来触达和让事件负责人感知到 。
【内容生产实时事件流平台-Core】会定时计算出事件波动绝对值 , 然后【内容生产实时事件流平台-异动感知】会上报到时序数据库(prometheus)中 。
这样在时间轴上就会形成数据的同环比 , 再将这些数值对接到【告警平台】就可以打通数据波动异常感知 。
比如 , 我们的【安全对账】能力 , 从统一监控到统一告警触达 。
监控面板是被动式的 , 需要人主动去看 。
当触发一定的监控阈值之后 , 需要通过【告警平台】统一收口到一个群里 。 这样可以形成有效的跟踪和响应 。
作为平台能力 , 一旦用户收到异动告警 , 就需要通过一些工具快速定位到具体的稿件 。
平台提供一站式【问诊台】来快速定位监控发现的异常数据 。
但是异动的类型不同 , 对告警的相关阈值和频率也不同 。 不同的事件类型 , 紧迫程度是不同的 , 所以不可能是一个固定的规则 。
根据我们的经验 , 总结出告警持续优化的一个迭代模型 , 异动感知的相关阈值设计 , 规则设置、频率设置等都是一个不断打磨的过程 。
04基于实时事件流搭积木
整个内容生产实时事件流平台的架构核心思想 , 是通过收集沉淀稿件全生命周期的事件 , 并且打通事件数据让具备全链路trace能力 。
有了这样的基础底座之后我们可以基于这些事件数据提供一整套的【全链路业务观测、感知、快速定位能力】 。
有了这套东西 , 我们试着回答前面的问题 。
1、平台每天生产的稿件中 , 优质、大V、党央媒、商单稿件的生产效率如何?有没有被block?
基于【耗时分位统计】能力 , 稿件各个事件耗时被计算出来 , 就可以看到生产效率问题 。 (优质、大V、党央媒、商单=aids\\up_type)
基于【事件丢失统计】能力 , 可以看到关键事件是否缺失 , 如果缺失说明流程出现中断 , 需要快速干预 。 (优质、大V、党央媒、商单=aids\\up_type)
2、下游转码、审核、开放等抖动 , 对大盘影响多少?绝对值多少?又有多少重点稿件受到影响?
基于【耗时分位统计】能力 , 可以看到P80\\P90\\P999等延迟占比 , 大概可以计算出影响多少稿件 。
基于【分位耗时AIDs】能力 , 可以在后台快速拉出具体的稿件aids , 用来手动恢复 。
3、某个大V的稿件迟迟没开放 , 知道卡在哪个环节了吗?如何主动发现?
基于【全链路trace】能力 , 可以根据aid\\uid快速定位事件的卡点位置 。
基于【事件丢失统计】能力 , 当出现关键事件(可以定义需要关心的事件)缺失可以主动感知到 。
4、所有开放的稿件 , 是否全部进行过安全审核?有没有漏审?
基于【事件段对账】能力 , 可以精确匹配某个稿件是否缺少某个处理事件(如 , 安全审核等) 。
【全链路业务trace】
非常高频的排障工具就是全链路业务trace能力 , 基本所有的卡点通过查看trace基本就知道卡在哪里 , 并且可以看到各个事件携带的关键数据 。
前面讲过 , 要想将客户端和服务端的事件完全链接起来 , 需要经过两个查询步骤 。 通常我们查询的入参是AID , 所以查询是反着找就行了 。
先通过AID找到当初【投稿】时候的server_trace_id , 然后再通过这个server_trace_id去查找当初【客户端】投稿时传进来的client_trace_id 。
trace会展示每个事件之间的duration 。
我们也可以查看每个节点的携带数据 , 并且也可以下钻当前事件的具体rpc调用trace(opentrace链路) 。
【内容生产耗时统计】
有了前后关联的事件数据 , 我们就可以很方便基于事件之间的duration , 计算出耗时分位 。
基于分位占比 , 可以动态计算出各个分位区间的稿件绝对值 。
由于不同类型的稿件 , 视频内容和大小是不一样的 , 所以会按照特定的稿件类型来查看耗时 。
现在基本可以做到将整个耗时和稿件量形成动态表格dashboard 。
在计算事件之间的耗时有一个小技巧分享下 , 因为我们的事件数据是行形式的 , 但是计算要换成列形式的 。
这里可以借用开窗函数 , 用aid进行分区 , 然后按照时间+事件排序 , 直接读取再通过lagInFrame()拿到每个分区的末尾行数据 。
select
aid
lagInFrame(event_time) over win as previous_time
event_time
from
xxx
where
xxx
window win as (partition by aid order by event_timeevent_key)
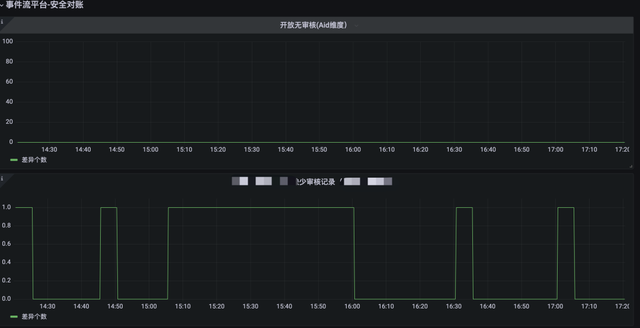
【内容安全实时对账】
所有生产的稿件内容 , 开放出去是一定要经过层层安全审核才能观看 。 如果出现高危风险的内容露出 , 那么危险程度非常之大 , 下架关站都是有可能 。
简单理解 , 需要对稿件的常规信息或介质(标题、封面、简介、视频)进行过审 , 系统设计原则就是没有审核过的稿件是不能开放的 。
由于各种原因可能会导致未经审核的稿件介质漏审开放 , 需要有一种保底安全检查机制 , 发现那些漏审的稿件介质 。
按照稿件的处理流程 , 我们只需要以【稿件开放】为锚点 , 回查【审核通过】事件 , 并且相关的媒介信息要完全能对上 。
也就是开放的稿件是一定能找到之前的审核通过事件 。
但是我们业务上有一种场景【延迟开放】稿件 , 就是稿件是在将来的某个时间在开放(特定节日、有意义的时刻等) 。
这种类型的稿件 , 所有流程和普通的稿件没有太大差异 , 只是开放的时候有一个异步JOB去扫描何时开放 。
这种稿件的对账有个比较难处理的就是 , 由于我们的事件clickhouse存储是有时间限制的(可以设置很大 , 但是有上限) , 就会导致开放的稿件找不到审核的记录 。
Aid:101010的稿件由于数据较久 , 已经被删除 。 回查的时候将找不到 , 导致对账误报 。
有两种处理办法 , 一种是放宽全表的存储时间 。 二种是单独将关键事件(需要回溯较久历史的)放入hive中 , 在对账任务中合并这两种数据源 。
05 总结
通过全局事件收集 , 让业务对象具备event-sourcing能力 , 让我们有了精确洞察“生产效率“的工具 。
虽然不同的行业和领域 , 对于”内容生产“的物料有所不同 , 但是站在数字化角度来看 , 一切都是需要和可以监控和跟踪的 , 且是科学和经济的最有效方法 。
有了这一套“内容生产实时事件流平台”之后 , 我们将逐步渗透到不同的层面和位置 , 观测和跟踪内容生产不同阶段的问题和改进点 。
业务观测体系化建设 , 重点是聚焦”企业经营“层面的业务对象 , 一般比较容易被忽视 。
研发倾向证明技术系统有没有故障 , 服务质量(SLA/SLO)是否达标 , 但是忽视了信息系统本质是企业数字化生产系统 , 无论是面向toC还是面向toB , 业务健康度也是需要指标来衡量的 。
我们在业务观测上潜行实践还是有不少收获 , 后续有机会再分享 , 也欢迎一起交流学习 。
-End-
【内容生产全链路业务观测体系建设】作者丨plen
推荐阅读










- 全新影像旗舰登场!vivo X200系列预热详解,超越影像的惊喜
- 面向全球25大市场,Zalando AI购物助手启动上线
- 英特尔酷睿Ultra 200K系列上架 较14代全面降价
- 苹果CEO重磅宣告:中国有望超越美国,成为iPhone全球第一大市场
- 没有华为鸿蒙的位置,比尔盖茨称,全球只能有2个手机系统
- 什么是全画幅相机
- 全面取消!告别“套娃”收费,电视机顶盒即将退出历史舞台?
- 鸿蒙生态加速迈向全面商用
- 全能骁龙8Gen3旗舰——iQOO12,那是非常值得体验的
- 全新vivo X200系列即将震撼来袭!性能大突破,没网也能通信