
文章图片

文章图片

文章图片

文章图片

文章图片

文章图片
文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

导读 本文将分享面向真实监控场景的多模态视频理解 。
主要内容包括以下几大部分:
1. 多模态视频理解任务介绍
2. 真实监控视频数据集背景
3. 多模态视频理解小模型介绍
4. 多模态视频理解大模型介绍
5. 问答环节
分享嘉宾|袁彤彤 北京工业大学 讲师
编辑整理|晏世千
内容校对|李瑶
出品社区|DataFun
01
多模态视频理解任务介绍
首先来介绍一下视频理解有哪些场景 。
1. 视频字幕生成
视频字幕生成是视频理解任务之一 , 这项技术可以用于生成电影字幕或视频描述等 。
除了视频字幕生成外 , 研究还包括密集视频字幕生成 。 该技术是针对未剪辑的长视频 , 密集地生成与画面内容相关的文本描述 。 评估标准就是生成字幕的质量 。
2. 视频时刻定位
第二个与视频理解相关的任务是视频时刻定位 。 这项任务的目标是从未剪辑的长视频中检索出与给定查询语句相匹配的具体时刻(即起始时间和结束时间) , 主要用于检索场景 , 例如在长视频中寻找特定的行为或事件 。 用户可以通过输入查询语句和视频 , 获得与查询相关的特定时间段 , 应用场景较为多样 。
3. 多模态异常检测
在监控视频领域 , 常用到多模态异常检测这一技术 。 传统的异常检测主要关注视频画面的大规模变化或异常行为 , 如打架或车祸等 。 随着技术进步 , 特别是 GPT 的发展 , 现在可以在异常检测过程中融入文本信息 。 具体来说 , 视频对应的文本描述可以作为模型的额外输入 , 通过融合文本和视频特征来提升异常检测的效果 。
02
真实监控视频数据集背景
1. 监控领域研究现状
当前监控领域的研究主要关注于识别监控视频中的异常事件及其类别 , 并且通常需要预先定义这些类别 。 这种方法对于未知类别的识别较为困难 , 从而影响技术的泛化性能 , 并且未能深入理解视频内容的深层语义信息 。 在传统的研究中 , 对于一段视频 , 常见的标注包括判断其是否异常以及具体的异常类别(如事故) 。 此外 , 下游任务通常包括异常检测和异常类别的分类 , 以及视频中的目标识别等任务 。
相比之下 , 我们的团队提出了不同的研究方向 , 即对监控视频进行更为详细和细粒度的文本描述标注 。 这种新颖的方法来处理监控视频数据 , 重点在于采用了更丰富的标注信息 。 与传统方法相比 , 我们的标注不仅限于简单的异常事件分类 , 而是包含了更加详细和细粒度的描述 , 如人物特征和场景细节等 。 这种详细的标注使得我们可以执行更多种类的任务 , 从而极大地扩展了监控视频分析的应用范围 。
2. 已有的监控视频数据集
现有的监控视频数据集 , 如 UCF crime 早期的数据集 , 主要用于异常检测研究 。 这些早期数据集的特点是视频数量有限、平均视频时长短 , 并且标注信息主要集中在简单的异常类别上 , 如错误的方向或未付费通过地铁闸机等行为 。 例如 , Avenue 数据集会标注路上奔跑等异常行为 。
2018 年提出的 UCF-Crime 数据集相对于早期数据集有所改进 , 包含了更多的视频(数量显著增加) , 总时长达到 128 小时 , 并且异常类别更加多样化 , 共有 11 种 。 然而 , 这些数据集普遍缺乏对事件深层次语义的描述信息 , 这限制了它们在多模态视频理解领域的应用 。
3. 多模态监控数据集 UCA 介绍
为了克服这些局限性 , 我们构建了一个新的大规模多模态监控视频数据集——UCA 数据集 。 该数据集基于真实的 UCF crime 监控视频 , 提供了更详细的视频文本标注 , 旨在支持更广泛的多模态视频理解研究 。
我们对监控视频中的每一个事件进行了详细的语义级别标注 , 这些标注由人工完成 。 构建的多模态监控数据集称为 UCA 数据集 , 其中包含了总计 23000 多条语义标注 , 用于描述视频中的正常或异常行为事件及其起始时间 , 时间精度达到了毫秒级(精确到 0.1 秒) 。
在标注过程中 , 我们特别注重数据的语句描述部分 , 要求标注人员尽可能详细地描述事件 , 每条描述平均包含约 20 个单词 , 被标注的视频总时长达到 110.7 小时 。
图片中提供了一个标注示例(从视频开始的时间:01:34.4 到结束的时间 01:45.6) , 每个视频片段都有对应的起始时间记录 , 并附带详细的语句描述 。 (见论文:Towards Surveillance Video-and-Language Understanding: New Dataset Baselines and Challenges. CVPR2024.)
4. 多模态监控数据集标注指南
在标注过程中 , 我们向标注者提供了详细的标注指南 。 指南强调了以下几个要点:
- 细粒度标注:要求标注者提供详细的注释 。
- 时间记录:准确记录事件发生的时间 。
- 描述长度:描述事件时应长短结合 , 避免语句过长 。
- 动作描述:重点关注视频中的画面变化 , 要求对动作进行清晰、精准的描述 。
5. 多模态监控数据集统计信息
数据集的相关统计信息显示 , 标注视频的时长分布如下:
- 最常见的视频长度集中在5 到 10 秒;
- 大多数视频事件的时长不超过 30 秒;
- 少数事件涉及的动作持续时间较长 , 超过 40 秒;
- 平均而言 , 每个事件注释的时长大约为 16.7 至 16.9 秒 。
- 使用 10 到 20 个词进行描述的情况最为常见;
- 其次是使用 20 到 30 个词进行描述的情况 。
利用该数据集 , 可以开展多项针对真实监控场景下的多模态学习任务 , 具体包括:
- 视频时刻定位:通过学习视频内容 , 识别与给定查询语句相关的活动发生的具体时间 。 例如 , 在示例中 , 系统能够预测出活动开始的时间点 。
- 视频字幕生成:对于给定的一段视频 , 系统能够生成相应的文本描述 , 实现“观看视频并叙述”的功能 。
- 密集视频字幕生成:对未经过裁剪的完整视频进行处理 , 连续描述视频中的所有行为事件 。
多模态视频理解小模型介绍
1. 多模态监控视频理解任务
【面向真实监控场景的多模态视频理解】本研究涉及的多模态监控视频理解任务采用了一种通用的模型框架 , 该框架适用于不同规模的模型(无论是大型模型还是小型模型) , 主要组成部分包括:
- 视频编码器:负责处理和提取视频帧的特征 。
- 文本编码器:用于处理文本数据 , 如查询语句或描述性文本 。
- 多模态融合模块:整合视频和文本编码器输出的特征 , 形成统一的多模态表示 。
- 预测头:用于特定下游任务的预测 , 如视频时刻定位、视频字幕生成以及多模态异常检测等 。
- 视频时刻定位:确定视频中特定事件的发生时间 。
- 视频字幕生成:为视频生成描述性的文本字幕 。
- 多模态异常检测:检测视频中的异常行为或事件 。
2. 视频时刻定位模型介绍
在视频时刻定位任务中使用的几种基准方法包括:
- CTRL:被视为最经典且受关注的方法之一 。 采用滑动窗口技术评估每个窗口内视频片段与查询语句之间的匹配度 。
- SCDM (Semantic Conditional Dynamic Modulation):引入了语义条件动态调制机制 , 使用锚点框进行检索 , 调整搜索范围以匹配查询语句 。
- 2D-Tan (Two-Dimensional Temporal Attention Network):基于锚点框的方法 , 使用二维特征图进行检索 , 通过二维特征图寻找与查询最匹配的时间段 。
- Moment Diffusion:首次将扩散模型应用于视频时刻定位 。 在时间轴上引入噪声并逐步扩散 , 以确定目标时间段的起始点 。
在基准实验中 , 我们采用了 IoU(阈值)作为评估指标 , 考察了不同方法在监控视频上的召回率(recall)表现 。 实验结果表明 , 在真实监控视频场景下 , 这些方法的表现较差 , 召回率普遍低于 10% 。
在进行模型训练时 , 我们使用了在 Sports-1M 数据集上预训练的 C3D 模型来提取视频特征 。
结合 skip-thought 技术 , 将视频特征与文本特征一同输入到语句编码器中 , 以获取查询语句的特征 。 这些特征随后被用于执行视频时刻定位任务 TSGV 。
这些基准实验的结果显示 , 视频时刻定位任务在真实监控视频场景下具有较高的难度 , 现有方法的性能表现相对较弱 。
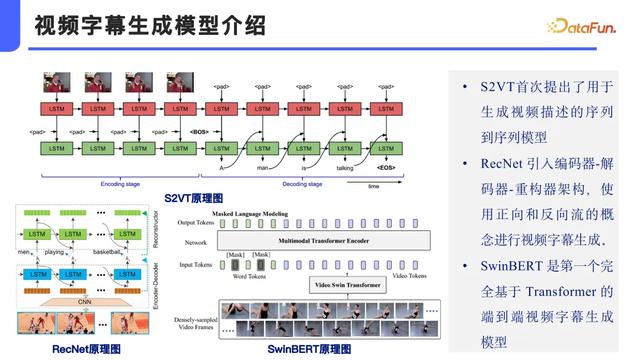
3. 视频字幕生成模型介绍
下面讨论一下视频字幕生成领域的几个关键模型 。 在 SwinBERT 出现之前 , S2VT 模型首次提出了利用序列到序列架构来描述视频内容的方法 。 S2VT 模型包含多个 LSTM 模块 , 这些模块共同作用于视频序列的处理 。
后期 , 这一概念进一步发展 , 通过引入 ResNet 编码器-解码器架构 , 并添加重构模块 , 来改进视频字幕的生成质量 。 SwinBERT 作为一个重要的里程碑 , 是首个完全基于 Transformer 架构的端到端视频字幕生成模型 。 由于其在视频理解方面的显著优势 , SwinBERT 成为了本研究的重点关注对象 。
在基准实验部分 , 我们评估了多种视频字幕生成方法 , 包括之前提到的 SwinBERT 和 CoCap 等模型 , 以及其他未提及的方法 。 这些方法使用的特征类型有所不同 , 有些采用传统的 CNN 提取特征 , 而 SwinBERT 和 CoCap 则采用了基于 Transformer 的架构 。
评估指标涵盖了双语评估基准(BLEU)、显示范排序翻译度量、基于摘要导向的评估以及一致性图像描述评估(CIDEr) 。 其中 , CIDEr 被认为是最综合的评价指标 , 通常用 \"C\" 表示 。 从实验结果来看 , 在这些模型中 , SwinBERT 在 CIDEr 指标上的表现最佳 , 但在监控视频任务上的整体性能仍有待提高 , 表明此类任务对现有模型而言仍具有较大挑战性 。
4. 监控视频多模态异常检测
在多模态异常检测方面 , 现有的方法源自 CPR W 2023 提出的一种技术 , 该方法利用预训练的 SwinBERT 网络对输入视频生成文本描述(caption) , 并将这些文本描述与视觉信息融合 , 以此来识别视频中的异常行为 。
与原有方法不同之处在于 , 新方法使用了针对监控视频训练的 video caption 模型 , 而非传统视频数据集训练的模型 。 具体而言 , 新方法将监控视频上生成的 caption 与原方法中的一般视频描述 caption 进行了融合 , 并将这两种 caption 与视觉特征相结合 , 以更有效地判断视频中的异常情况 。 这里边主要的区别就是我们又额外引入了一个在自己的数据集 UCA 上预训练好的一个 SwinBERT 模型 。
为了评估动态异常检测的效果 , 我们采用了 AUC(ROC 曲线面积)作为评价指标 。 结果显示 , 我们的方法相较于原有技术有所提升 。 通过对比具体的 video caption 实例 , 我们发现 , 在监控视频上训练的 video caption 模型能够更有效地检测出异常行为相关的词汇 。
相比之下 , 使用传统视频数据集训练的 SwinBERT caption 模型未能准确识别视频中的异常行为 。 而我们的方法则能够更准确地捕捉到异常行为 。 与传统方法相比 , 新方法对整体的异常检测任务具有显著的积极作用 。
5. 多模态模型在监控数据集上的挑战
上图展示了不同视频数据集上模型性能的对比 。 具体而言 , 在时空地面真值生成(TSGV)任务上 , 模型在 ActivityNet Captions 数据集上的性能约为 65 , 在 TACoS 数据集上下降至约 39 , 而在 UCA(Urban Camera Activity)数据集上进一步降至 10% 以下 。 对于视频字幕生成(VC)任务 , 模型在 MSRVTT 数据集上的 CIDEr 指标为 53.8% , 在 VATEX 数据集上为 73 , 但在 UCA 数据集上仅为 25% 。 更进一步 , 在密集视频字幕生成(Dense Video Captioning)这一更具挑战性的任务上 , 所有模型的表现均不佳 , 其中 UCA 数据集上的 CIDEr 指标仅为 8 点多 , 远低于其它数据集上的 20 多 。 这些结果表明 , 相比于传统视频数据集 , 监控视频数据集上的视频理解任务更为困难 。
主要的挑战来自于所面对的数据域不同 , 监控视频画面质量较差 , 且由于距离摄像头远近不一 , 目标主体可能会较?。 涣硗?, 异常行为常常是突发的 , 因此捕捉困难 。
要提高对监控视频内容的理解 , 应关注以下几点:
- 视频和语言模态对齐;
- 视频时间信息特征融合;
- 关键异常行为定位;
- 更全面的语义信息挖掘 。
多模态视频理解大模型介绍
大型多模态模型在动态视频理解方面展现了出色的能力 。 例如 , GPT-4 以及 Google 发布的其他多模态大模型 , 在视频理解及生成任务上表现优异 , 能够有效地处理复杂的视频内容 。
1. 大语言模型帮助构建多模态模型
我们也可以借助大语言模型来构建多模态模型 , 具体步骤包括:
- 核心构建:以大语言模型作为核心基础 。
- 模态融合:
- 视觉编码:将视觉信息编码并融入模型 。
- 语言信息:进一步集成语言数据 。
- 音频信息:还可以加入音频模态的数据 。
- 对齐语义空间:确保所有模态的信息都能映射到大语言模型的统一语义空间内 。
2. 多模态大模型用于视频字幕生成的框架
我们提出了一种利用大语言模型来处理监控视频并生成视频字幕的新框架 , 具体包括以下几个步骤:
- 视频编码:首先对输入的监控视频进行编码 , 提取出视频中的视觉特征 。
- 模态融合:通过 Q-Former 或其他连接机制将提取到的视觉特征与大语言模型相结合 。
- 多模态模型构建:使用诸如 MiniGPT-4、VideoChat2 和 VideoChat2 等大语言模型作为核心组件 , 构建一个多模态模型 。
- 文本生成:将视觉特征转换为文本标签(tag-to-text) , 生成初步的文字描述 。
- 文本润色:使用 MOSS 和 StableLM 等额外的大语言模型对生成的文本进行优化和润色 , 以提高描述的质量 。
- 输出:最终输出是对监控视频内容的理解和描述 。
3. 多模态大模型视频字幕生成结果展示
在这项研究中 , 我们对比分析了未经微调的模型直接应用于视频内容理解的效果 。 从几个例子中可以看出 , 大多数模型的回答并不准确 。 然而 , 在这些模型中 , VideoChat2 表现相对较好 。
以上是一些具体的评测数据 。 VideoChat2 模型在 CIDEr 指标的得分达到了 20 多分 , 而其它模型在这个指标上的得分只有 10 分左右 , 显示出较大的性能差距 。
进一步分析表现较好的 VideoChat 和 VideoChat2 模型 , 我们发现 VideoChat 无法识别出监控视频中的异常行为 , 而 VideoChat2 则偶尔能够检测到异常行为 。 尽管如此 , VideoChat2 在描述异常行为的具体主体(即涉及异常行为的对象)时仍然存在错误 。
这些观察为我们提供了改进方向 , 特别是在提高模型识别和准确描述异常行为方面 。
4. 多模态大模型在监控域数据集上的微调
为了改进现有模型的表现 , 计划对一个多模态大模型进行微调 。 使用人工标注的数据集 UCA 作为微调数据来源 , 并选择 VideoChat2 作为基准模型 , 该模型由上海人工智能实验室在 2024 年 CVPR 上发表 。 VideoChat2 采用三阶段微调流程:
- 第一阶段:冻结视觉模块 , 只更新连接器模块(Q-former) 。
- 第二阶段:同时更新视觉模块和连接器模块 , 冻结文本模块 。
- 第三阶段:使用 LoRA 对文本模块进行高效微调 。
我们对第三阶段进行了微调 , 使用 UCA 数据集的视频输入来更新视觉编码器 , 并利用对应的视频字幕数据来微调文本部分 。 通过 LoRA 更新大语言模型部分 , 微调了大约三个 epoch 。
在表格中的结果表明 , VideoChat2 原本 CIDEr 指标在 10% 左右 , 经过三轮微调后 , finetune_VC2_stage3 在测试集上的 CIDEr 指标提高到了 25% 左右 , 显示出了显著的改进效果 。
5. 多模态监控大模型后续研究
对于多模态监控大模型的后续研究工作主要在两个层面:
- 数据层面 , 计划构建用于视觉问答(VQA)任务的指令数据 , 并利用大模型辅助生成问题及答案 。 鉴于目前数据量约为 2 万条 , 相对较少 , 将采用自动生成模型来增加标注文本的数量 , 尽管这些自动生成的文本质量可能较低 。
- 模型层面 , 已初步加入了异常帧图像检测模块 , 旨在更专注于异常行为分析 , 并将其作为一种新的模态输入 。 最终目标是开发一个多模态监控视频理解的大模型 , 并发布一个全面且功能强大的综合模型 。
最后欢迎大家关注我们的工作 , 相关论文已经发布 , 同时我们也开源了所使用的数据集 , 感兴趣的朋友可以通过提供的网址访问数据集 , 未来的工作进展也会在这个网页上更新 。
以上就是本次分享的内容 , 谢谢大家 。
05
问答环节
Q1:用户提出了一个关于基于视频监控的大模型在实际应用中抽帧处理的问题 。 具体来说 , 如果每秒只能提供一帧图像 , 这样的低帧率是否会严重影响模型的性能?特别是在传输路数较多的情况下 , 如何处理这种情况?
A1:对于低帧率传输可能导致的问题 , 可以通过在端侧部署模型来解决 。 具体做法是不在服务器端传输完整的视频流 , 而是先在前端使用视频字幕生成模型将视频内容转化为文本描述 , 并优先传输这些文本信息 。 这样可以在不影响实时性的情况下快速检索和定位视频中的关键部分 , 随后再传输相关的视频片段 。 这种方法有助于减轻网络带宽的压力并提高系统的响应速度 。
Q2:在实验中视频帧的抽取频率是多少 。 即在进行视频处理时 , 每秒从视频中抽取多少帧用于分析或进一步处理?
A2:尝试了不同的帧抽取频率 , 包括每秒 8 帧和 16 帧 。 原始视频的帧率为 30 帧/秒 , 但为了适应模型的输入限制 , 实际处理时减少了帧数 , 具体保留了多少帧已记不清 。 由于模型不能处理过长的视频输入 , 因此对帧数进行了相应的调整 。
Q3:如果将大模型或多模态大模型应用于实时处理多个摄像头视频流的场景中 , 会有哪些处理方法 。 考虑到实际应用中的算力限制 , 直接使用这些模型可能无法实现?
A3:为了实现实时处理多个摄像头视频流的目标 , 可以采用以下几种方法:
开发轻量化模型:创建计算负担较小的模型 , 以便更好地适应实时处理的需求 。
数据下采样:减少输入数据的复杂度 , 例如降低视频帧率 , 从而简化处理流程 。
多级处理:在前端进行初步筛选 , 例如过滤掉无人活动的视频片段 , 仅将含有有价值信息的数据传输到后端进行进一步处理 。
以上就是本次分享的内容 , 谢谢大家 。
推荐阅读












- 手机上怎么赚钱?10个真实有效的赚钱app,值得拥有!
- LangSmith 调试监控工具使用入门
- 手机出现这些现象,说明你被\监听\了,早点关闭,摆脱监控
- 手机充电时发热发烫是怎么回事?原来是这两个开关没打开,学会了真实用
- 2024.9.28印度或将中国品牌监控设备从供应链中剔除
- 红米Note14 Pro+线下上手体验:不吐不快,说说真实感受
- iPhone16首周销量比iPhone15少12.7%,真实数据比这个还差吧?
- 真实体验说话,三星S24Ultra的直屏,是升级还是降级?
- 为什么越来越多的人都不买华为手机了?这4个原因很真实
- 【真实测试】影驰RTX4070TIS挑战黑神话悟空,2K最高画质