千万级数据的全表update的正确姿势
文章图片
前言
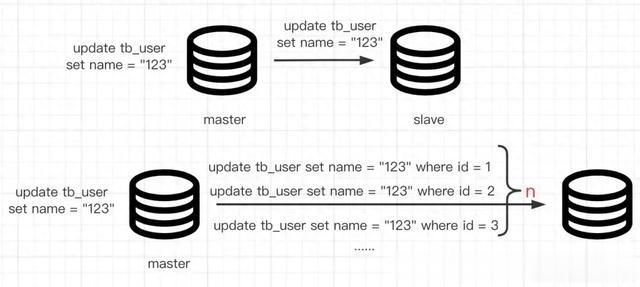
有些时候在进行一些业务迭代时需要我们对Mysql表中数据进行全表update , 如果是在数据量比较小的情况下(万级别) , 可以直接执行sql语句 , 但是如果数据量达到一个量级后 , 就会出现一些问题 , 比如主从架构部署的Mysql , 主从同步需要需要binlog来完成 , 而binlog格式如下 , 其中使用statement和row格式的主从同步之间binlog在update情况下的展示:
我们当前线上mysql是使用row格式binlog来进行的主从同步 , 因此如果在亿级数据的表中执行全表update , 必然会在主库中产生大量的binlog , 接着会在进行主从同步时 , 从库也需要阻塞执行大量sql , 风险极高 , 因此直接update是不行的 。 本文就从我最开始的一个全表update sql开始 , 到最后上线的分批更新策略 , 如何优化和思考来展开说明 。
正文
直接update的问题
我们前段时间需要将用户的一些基本信息存储从http转换为https , 库中数据大概在几千w的级别 , 需要对一些大表进行全表update , 最开始我试探性的跟dba同事抛出了一个简单的 update 语句 , 想着流量低的时候执行 , 如下:
update tb_user_info set user_img=replace(user_img'http://''https://')这里也给大家提一个醒 , 在存储图片等 path 路径时 , 经历不要存储协议和域名之内的前缀部分 。 如果要改 http 协议、域名之类的就要涉及批量更新等操作 , 同时存储的容量也会不必要的增加 。
深度分页问题
上面肯定是不合理的会给主库生成binlog、从库接收binlog写数据带来很大的压力 , 于是就想使用脚本分批处理如下所示:写一个这样的脚本 , 依次分批替换 , limit的游标不断增加 。 大概一看是没有问题的 , 但是仔细一想mysql的limit游标进行的范围查找原理 , 是下沉到B+数的叶子节点进行的向后遍历查找 , 在limit数据比较小的情况下还好 , limit数据量比较大的情况下 , 效率很低接近于全表扫描 , 这也就是我们常说的“深度分页问题” 。
update tb_user_info set user_img=replace(user_img'http://''https://') limit 11000;in的效率
既然mysql的深分页有问题 , 那么我就把这批id全部查出来 , 然后更新的id in这些列表 , 进行批量更新可以吗?于是我又写了类似下面sql的脚本 。 结果是还不行 , 虽然mysql对于in这些查找有一些键值预测 , 但是仍然是很低效 。
select * from tb_user_info where id> {index limit 100;update tb_user_info set user_img=replace(user_img'http''https')where id in {id1id3id2;最终版本
最终在与dba的多次沟通下 , 我们写了如下的sql及脚本 , 这里有几个问题需要注意 , 我们在select sql中使用了这个语法/*!40001 SQL_NO_CACHE */ , 这个语法的意思就是本次查询不使用innodb的buffer pool , 也不会将本次查询的数据页放到buffer pool中作为热点数据的缓存 。 接着对于查询强制使用主键索引 FORCE INDEX(PRIMARY), 并且根据主键索引排序 , 排序后的数据进行id游标的筛选 。 最后执行update更新时 , 由于我们在前面的sql中查询到的就是已经排序后的主键 , 因此可以对id执行范围查找 。
select /*!40001 SQL_NO_CACHE */ id from tb_user_info FORCE INDEX(`PRIMARY`) where id> \"1\" ORDER BY id limit 10001;update tb_user_info set user_img=replace(user_img'http''https') where id >\"{1\" and id <\"{2\";我们可以仅关注第一个sql , 如下图所示 , 是buffer pool大概内容 , 我们可以通过这个no cache的关键字 , 对批量处理的数据进行强制指定不走buffer pool , 不把这些冷数据影响到正常使用的缓存内容 , 防止效率的降低 , 其实mysql在一些备份的动作中 。 使用的数据扫描sql也会带上这个关键字 , 防止影响到正常的业务缓存;接着需要强制对当前查询指定的主键索引 , 然后进行排序 , 否则mysql有可能在计算io成本进行索引选择时 , 选择其他的索引 。
使用这样的方式对数据库进行批量更新可以通过一个接口来控制速率 , 对于数据库主从同步、iops、内存使用率等关键属性进行观察 , 手动调整刷库速率 。 这样看是单线程阻塞的操作 , 其实接口也可以定义线程个数等属性 , 接口中根据赋予的线程个数 , 通过线程池并行刷数据 , 从而提高全表更新速率的上限 , 同时对速率进行控制控制 。
其他问题
【千万级数据的全表update的正确姿势】如果我们使用snowflake雪花算法或者自增主键来生成主键id的话 , 插入的记录都是根据主键id顺序插入的 , 如果使用uuid这种我们怎么处理?当然是业务中就预先处理了 , 先把入库的数据提前进行替换 , 进行代码上线后再进行的全量数据更新了 。
推荐阅读












- 苹果iOS18.1.5能不能升级?优化不可思议,升级建议来了
- 旧 iPhone 升级至 iOS18 后续航实测结果出炉
- 荣耀66W超级快充充电器使用起来更放心
- ios18.0.1系统适应期已过,值不值升级?测试结果来了。
- 【深度观察】万亿独角兽诞生,“超级AI”要来了?
- vivo彻底急眼了,X100s突降847元,超薄直屏+100倍超级变焦
- 荣耀100 GT不简单:2K超级屏+6510mAh电池,香气扑鼻
- 迷你主机硬盘升级:必恩威CS2340系列2TB SSD固态硬盘
- 铠侠256g固态硬盘短路烧坏,免费教你维修硬盘找回数据
- 【OPPO】Reno12-全新配色-全新升级!