“书生”提出了一个新的范式,名为“混合参数共享”,从而开发一个名为“多面手”的通才模型。
具体来说,由于专家捕获的知识是相互关联的,当专家的特征融合为一个共享的表示形式时,再利用基于软共享的跨任务知识转移和基于硬共享的通用表示学习的方法,在不引入任务冲突的情况下在专家之间传递信息(特征转移),从而进一步提高了多任务训练的模型(专家)性能,即“通才”能力。
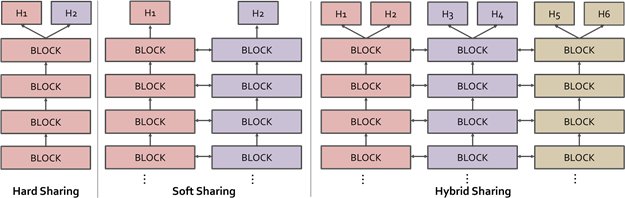
在结构上,通才模型是所有专家的一个相互关联的版本,因此可以把每个“专家主干”称为“通才分支”。此外,我们还可以根据训练相应专家的任务将通才中的每个分支分为图像、补丁和像素。但无论是软共享还是硬共享,都意味着从专家模型到通才模型的一次跃升。
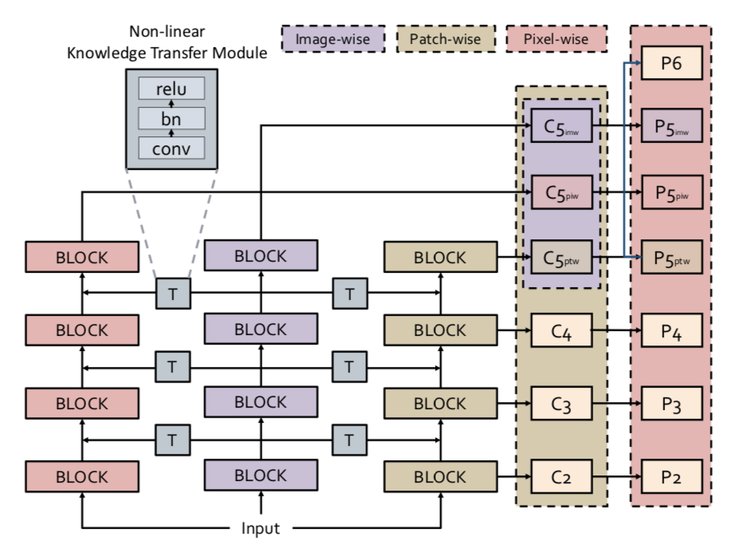
在经历了前三个训练阶段模块后,终于来到最后的任务迁移阶段 (Adaptation)。
这个阶段属于技术链条的下游,用来解决各式各样不同类型的任务,而这也是最考验“书生”举一反三能力的时刻。它需要在这个阶段把之前学到的通用知识,融会贯通地应用到不同特定任务中。
在此之前,很多迁移学习方法确实取得了很多进步,但问题是,这些方法既没有利用上游预训练中的隐含信息,也没有考虑到下游数据在少镜头场景中的不足。
因此,“书生”提出了一种Multi-stage Fine-tuning (MF)方法,缓解在数据较少的情况下传输的困难,再通过将上游数据编码成生成模型,即VQ-GAN,可以将预训练的模型转移到多个任务和领域,而无需每次都使用上游数据,而这也使得“书生”更具通用性和可扩展性。
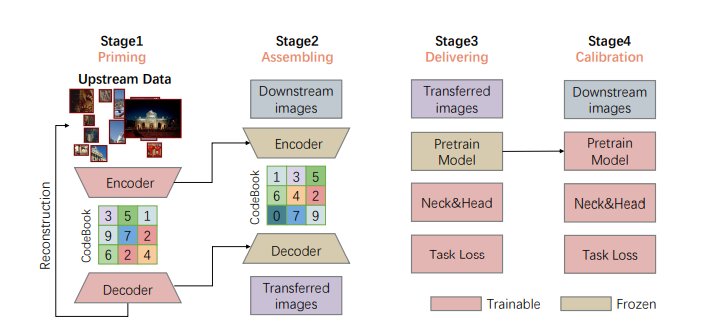
多级微调(MF)概述:VQ-GAN模型首先在第一阶段使用上游数据进行训练,然后在第二阶段由它重构下游数据。在此之后,第三阶段只对新增任务的特定参数进行重新表示的图像训练,第四阶段则通过下游数据对整个模型进行微调。
至此,一个具有持续学习能力的通用视觉模型终于出世。
而具体有哪些提升,不如看一下更直观的实验数据对比!
一网打尽视觉领域四大任务视觉领域,任务繁多,主流任务包含分类、目标检测、语义分割、深度估计四大类型。
在这四大任务中,最强大的视觉模型还是去年OpenAI发布的CLIP模型。但相比较而言,“书生”则在准确率和数据使用效率上都有所提升。
1、精度表现
通过对“书生”训练出的模型在GV-B上的评测对比,发现经过多阶段预训练的MetaNet精度表现优异。
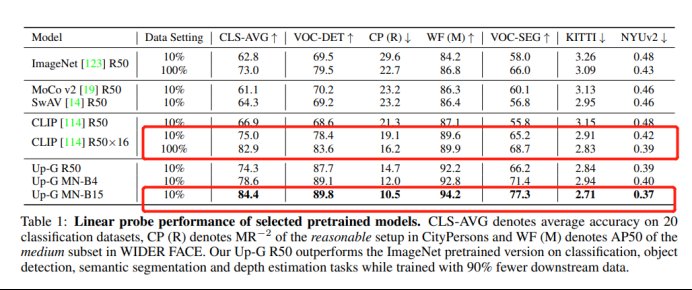
在ImageNet等26个最具代表性的下游场景中, “书生”在分类、目标检测、语义分割及深度估计等四大任务上,平均错误率分别降低了40.2%、47.3%、34.8%和9.4%。
书生(INTERN)与CLIP-R50x16在不同样本量上的性能对比,正确率展示
2、数据使用效率
“书生”在数据效率方面的提升尤为瞩目:只需要1/10的下游数据,就能超过CLIP基于完整下游数据训练的准确度。
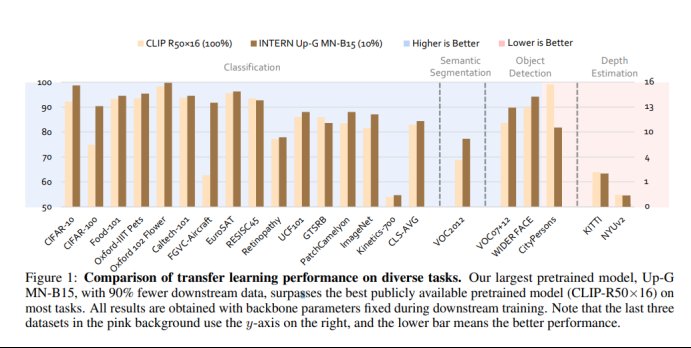
以CLIP-R50x16和Up-G MN-B15在GV-B的评测对比为例,分别在分类、目标检测、语义分割、深度估计四大类型的26个下游任务数据集上进行了评测,仅使用了10%数据进行训练的Up-G MN-B15模型,在绝大部分数据集上都能比使用了全部训练数据的CLIP-R50有更好的精度表现。这表明,经过多阶段预训练的MetaNet具有极强的泛化能力,能够在仅有少量的训练样本情况下,达到SOTA的精度表现。
推荐阅读















- 销售额|为什么聪明人买房只买89平米?
- 杨现领|浙江:一女子租住公寓空调是残次品只能住酒店,公寓管家不给报销
- |农民在宅基地建房,需要审批吗?加盖楼层属于违建吗?
- |公寓价格只有住宅价格的一半,我要不要买公寓房呢?
- 武汉|重磅!只认贷不认房!南昌限购区首套首付降至2成,奈何只针对……
- 长沙|交房,只能算开发商的及格线!
- 大牌|新家厨具选购只要零头价格!原来这些代工厂本身也是性价比超高的大牌
- 购房置业|如今的社会现状。房地产商是否需要改变观念?
- 商品房|购买期房能抵押贷款吗?三大风险需要提前知道!
- |开发商降价前的五个信号,只是好多人没干过,赶紧收藏啊