家人们,你们有没有这种苦恼?
搬一次家就换一次家具,那些又贵又重的家具既不好搬运,又不好全部带走。
下一次又重新购置一遍家具,浪费钱不说,关键是来来回回都做一样的事情!家具还没用过几次,利用率不高呀!
这种搬家的苦恼,就好比AI领域,做几个任务就需要开发几个高度定制的模型,不仅所需的数据采集量非常大,每次还都得从头标注。既提不起数据的学习效率,又耗费巨大的数据获取成本。
光是AI前端研究就耗费如此巨大的精力,更别提应用场景中数以万计的长尾任务。
那怎么办?
做一款通用的深度学习模型,才是关键。
通用,才是技术根本无论国内外,底层技术关注者都以设计出“通用模型”为己任。而打造通用模型的两个主战场,就是深度学习应用最广泛的两个方向:语言与视觉。
目前,通用语言模型(GLM)已经取得了令人瞩目的进展,比如BERT、T5和GPT-3,它们在应对广泛的语言下游任务时已经游刃有余。
相形之下,通用视觉模型(GVM)的研究迟迟未交出一份令人满意的答卷。
以往的大多数 GVM 研究主要利用一种监督信号来源,如 ViT-G/14 采用有标签监督,SEER 采用样本的不同增强之间的对比学习,CLIP采用图片文本对进行监督。如果是在单个监督信号下进行的预训练,这几种范式确实能够生成在固定场景下表现良好的模型。但如果用在场景多元、任务多样的下游场景,这些模型就难以胜任了。
比如现在最火的自动驾驶,汽车处于移动状态,既要看到路况,又要看到红绿灯,还要注意行人,甚至在智能座舱兴起后,还要和语言技术、LBS场景服务协同,这么多的感知数据与协同任务,这么多随机的新任务,无论在体量还是维度方面,都对视觉模型的要求极大提高。
这时,打造一款通用视觉模型,降低研发门槛,尤其是学术界的时间成本、资金成本,才能畅享下游的极致场景体验。
去年11月,上海人工智能实验室联合商汤科技、香港中文大学、上海交通大学发布通用视觉技术体系“书生”(INTERN),一套持续学习框架,用于系统化解决当下人工智能视觉领域中存在的任务通用、场景泛化和数据效率等一系列瓶颈问题。
前不久,上海人工智能实验室联合商汤科技发布通用视觉开源平台OpenGVLab,面向学术界和产业界开放其超高效预训练模型、超大规模公开数据集,以及业内首个针对通用视觉模型的评测基准。
这些开源技术,究竟有何魔力?
大力出奇迹,打造通用视觉模型“书生” (INTERN),就是练就通用视觉能力的底层技术。
从技术实现上讲,“书生”技术体系由由七大模块组成,包括三个基础设施模块和四个训练阶段构成。
三个基础设施模块分别为通用视觉数据系统(GV-D)、通用视觉网络结构(GV-A)、以及通用视觉评测基准(GV-B);
四个训练阶段分别为:上游基础模型训练(Amateur)、上游专家模型训练(Expert)、上游通才模型(Generalist)训练;以及下游的应用训练(Downstream-Adaptation)。
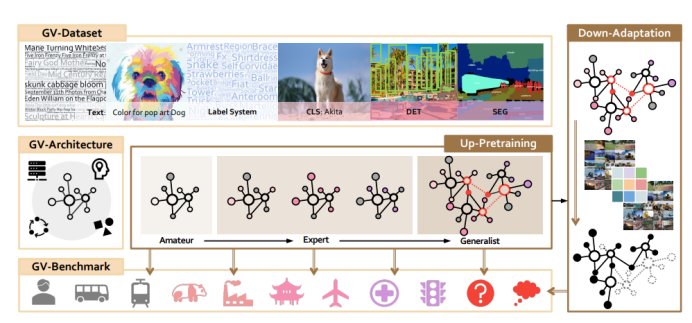
书生(INTERN)结构图
首先,通用视觉数据系统。
这是一个超大规模的精标数据集,拥有100亿个样本和各种监督信号,并依照四大视觉任务分别设置了四个数据子集:多模态数据GV-D- 10B分类标注的GV-Dc-36M、检测标注的GV-Dd-3M、分割标注的GV-Ds-143K。
另外,这一数据集还包含11.9万的标签系统,不仅涵盖了自然界的众多领域和目前计算机视觉研究中的几乎所有标签,还扩充了大量细粒度标签,涵盖各类图像中的属性、状态等。
推荐阅读














- 销售额|为什么聪明人买房只买89平米?
- 杨现领|浙江:一女子租住公寓空调是残次品只能住酒店,公寓管家不给报销
- |农民在宅基地建房,需要审批吗?加盖楼层属于违建吗?
- |公寓价格只有住宅价格的一半,我要不要买公寓房呢?
- 武汉|重磅!只认贷不认房!南昌限购区首套首付降至2成,奈何只针对……
- 长沙|交房,只能算开发商的及格线!
- 大牌|新家厨具选购只要零头价格!原来这些代工厂本身也是性价比超高的大牌
- 购房置业|如今的社会现状。房地产商是否需要改变观念?
- 商品房|购买期房能抵押贷款吗?三大风险需要提前知道!
- |开发商降价前的五个信号,只是好多人没干过,赶紧收藏啊