
文章图片
现如今 , 内容无处不在 , 随时可供访问!尼尔森 (Nielsen) 的一项研究发现 , 美国成人每天用于阅读、聆听、观看媒体以及与媒体互动的时间超过 11 小时 。 当下大家宅在家中 , 想必这个数值只会更高 。 可用内容层出不穷 , 您或许会想知道:是否存在一种定量方式 , 让我们能够深入了解可用文本?
文本挖掘也称为文本数据挖掘 , 指的是从文本撷取高质量信息的过程 , 其终极目标是从文本变量中提取度量数值 , 供定量建模之用 。
文本挖掘为何重要? 文本挖掘可用来找出简单的模式 , 也可用于复杂程度大得多的情感分析 。 可使用基本统计来进行简单的分析 , 如 , 对某个词被提及的次数进行计数 , 或者 , 计算出字母全大写词语的数量 。
获得汇总统计后 , 可以通过条形图等可视化功能 , 以图形方式显示出现频率最高的词语;也可以通过文字云 , 以富表现力的图像显示这些词语 。 若需要感受人们对某款产品或某个过程的感觉和态度 , 这项功能尤为实用 。
好消息!Minitab 最新版搭载全新 Python 集成 , 可供您充分利用文本挖掘!
让文本变得栩栩如生:探索葡萄酒评论和逆向文件频率 为方便说明 , 我们用一个简单的例子 , 分析对某葡萄酒的 5 个不同评论 。 通过 Minitab 调用 Python 来执行分析 , 您就可以拿到一份非常简单易懂的汇总统计表格 , 如下所示:
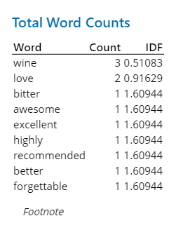
文章图片
如您所看到的 , 在 5 个评论中 , 词语“葡萄酒 (wine)”出现了 3 次 , 词语“喜爱 (love)”出现了 2 次 , 而其他词语均只出现 1 次 。 Minitab 还会提供每个词语的逆向文件频率 (IDF) , 其计算方法如下:
IDF = ln (N/DF)
其中 , N = 观测值数量(在这个案例中 , 总数 5 个评论中的全部评论) , DF = 出现特定词语的文件数量 。
从数学角度讲 , 若一个词语出现于所有观测值中 , 则其 IDF = 0 。 因此 , IDF 最低的词语出现次数最多 , 而只出现在一个观测值中的词语的 IDF 最高 。
在这个案例中 , 可以清晰看出 , “葡萄酒 (wine)”的 IDF 最低 , 因为其出现次数最多 。 基于这些汇总统计 , 我们可以推断 , 喜欢葡萄酒的人比不喜欢的居多 , 而且在总体上 , 评论是正面的 。
我们中有很多人偏好视觉资料 , 可以用文字云来查看此样本分析:

文章图片
如您所见 , “葡萄酒 (wine)”出现次数做多 , 因此字体最大;看一眼文字云即可看出总体评论呈正面 。
使用 Minitab 中的全新 Python 连接来实施文本挖掘 。 此前从未接触过 Python 也无妨 , 我们为您提供了 Python 安装和使用说明 。 成功安装扩展项后 , 便可以轻松在 Minitab 中持续执行标准文本挖掘任务 。
希望进一步了解可通过 Minitab 中的 Python 实现的功能?了解更高级的功能 , 例如 , 情感分析、词袋模型以及潜在语义分析请联系我们!

文章图片
【分析|有兴趣了解文本挖掘?利用Minitab中的Python 集成开启探索之旅!】
文章图片
推荐阅读












- 小铺|了解零食小铺零食店加盟经营攻略 为门店开业蓄力
- 消息资讯|创业的本质你了解多少?零食小铺零食店项目全分析
- 因为|你真的对刷牙了解吗?了解正确的刷牙方式和刷牙时间
- 分析|2021年中国柠檬酸供需现状与行业前景分析,受出口景气度上升价格持续上涨
- 我国|坚果炒货行业前景分析
- 分析|葡萄酒产业数据分析:2021年82%中国消费者购买且饮用过葡萄酒
- 分析|2022-2028年中国休闲零食行业市场运营态势及投资战略规划报告
- 分析|中国儿童零食产业深入解析报告(2022-2028)
- 天气|冬季减肥全攻略了解一下
- 食品|了解以下几点,从此创业不再难!